[Editor’s note: This post is the fifth in a series which collates and shares the content of workshops given during the recent Libraries Deliver: Ambition sector forums.]
Introduction
As mentioned in our earlier post, we offered a range of workshops during our sector forums in Newcastle, London, Bristol and Birmingham. In the latter 3 venues, not all the people at the event could attend all the sessions, so the Taskforce is using this series of blog posts to enable everyone to see the presentations and get a flavour of the discussions that took place. The workshop: ‘Libraries core dataset’ was held a total of 12 times, in 4 locations, and 137 people took part.

Workshop content
These sessions took the form of workshops, starting with an introduction from me on what the core dataset is and the data action in Libraries Deliver: Ambition, to define and publish a core dataset creating a transparent and automated (where possible) process to gather and share it.
The core dataset is intended to be a series of data which all library services will collect, use and publish. The plan is to have a consistent dataset which can be used to help inform and improve local library service delivery, as well as being used for advocacy purposes at local and national level (when aggregated). There may, of course, also be other data which authorities choose to collect in addition to this for their own local purposes. What that dataset should contain was the basis of the discussion at these workshops: what form it should take, how it is collected and the process of automating it will be a longer piece of work over the next year.
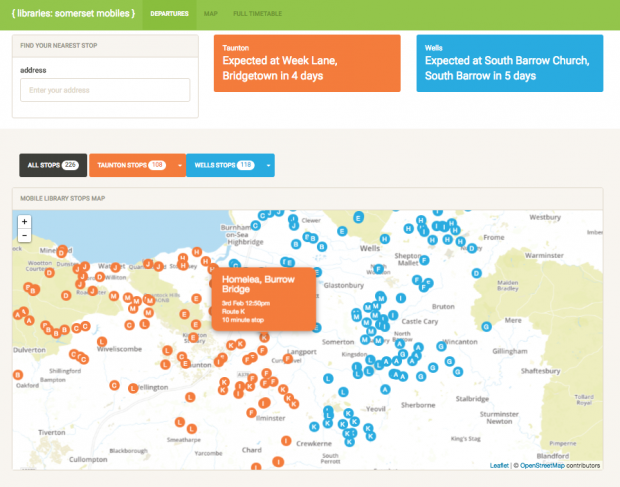
I talked about examples of where library and non library data is being used innovatively. For example, Libraries Hacked did some work a while ago on mobile library departures in Somerset.
I also talked about the work which Newcastle are doing in publishing their data and how they’re using it. They’ve run a couple of hackdays using their published data as well, more information on which can be found in a guest blog and via CILIP where they talked about their experiences of opening up data. Newcastle City Libraries are also looking for other authorities to publish their data too, so do speak to them about how they’re doing it if you’re interested.
I then talked about how government more widely is using data with:
- the GOV.UK performance platform which publishes performance data on government services
- the Local Government Association’s LG Inform platform for publishing and aggregating local government data - our blog on the evidence based planning workshop will go into more detail on that
- DCMS’ Taking Part survey and the online data analysis tools which were launched last year, meaning everyone can play around with the data far more easily and to a greater level than is published in the quarterly documents

Following this introduction, I then posed a series of questions to the group to get their views on the possible usage and content of a core dataset for libraries:
- What data do you currently collect?
- How do you share / use your data (both externally and internally)?
- What are the barriers / challenges which stop you collecting and sharing data?
- What data would be most useful for making decisions?
What people said on data currently collected
This included information on:
- Events
- Library members
- Wifi usage
- Computer usage
- School class visits
- Website hits
- Social media
- Online services including e-books, e-journals, e-audiobooks
- Everything in CIPFA, eg items borrowed, hours open, visitor figures, financial data
- Volunteer hours and types of sessions run
- Summer Reading Challenge
- Enquiries
- Stock
...and the list goes on! Libraries collect and hold a lot of data.
It was clear though that, while pretty much everyone collects information on, for example, events, the frequency and type of data collected varies hugely. This applied to most of the things libraries collect. We also talked about how counting things is easier which is why the majority of the data collected is quantitative. However, there are some authorities who are using different ways of getting more qualitative data via feedback forms and through other methods. I’ll be following up with those who are doing this, but please do get in touch to share how you’re collecting this type of data.
What people said on how they use data
As the first question showed, libraries collect a lot of data. But how is it used? Answers varied, but included:
- For performance management purposes, with reports to commissioners and councillors, corporate dashboards and comparisons across branches
- To complete CIPFA returns
- To apply for funding
- For advocacy purposes
- For business planning
The answer turns out to be not as much as it probably should be, with everyone generally agreeing that it’s currently not used particularly effectively. There are a number of reasons for this, some of which we touched on in the next question, but it was also suggested a few times that a lot of data is collected and kept ‘just in case’.
What people said were the barriers / problems
There was a pretty wide consensus on what people thought were the greatest barriers. These were:
- Limited staff and time to collect data
- Lack of people with data analysis skills
- Inconsistency in how information is collected, ie. visitor numbers
- No standard definitions which makes it hard to benchmark
- Issues with surveys - people enjoy anonymity in the library, the public view surveys as having a negative impact on a library
- Difficulty of separating data when co-located with other services
- Accessibility of the data, ie. it’s held centrally by the council or with partner organisations
- Relying on the wrong statistics; it’s difficult to compare across areas when current statistics don’t properly reflect activity in libraries
- Multiple systems counting data in different ways which makes it hard to interrogate across different platforms
- Old IT
- Carrying out effective evaluation is challenging
These will all need to be considered when establishing how the core dataset will be collected and used.
What people said about data they’d find most useful
The big three things people wanted was:
- Information on users, non users and lapsed users
- Being able to show how all the library is being used / the full range of services being provided, not just the number of books borrowed or PCs in use
- Qualitative data to show the impact of libraries around the 7 Ambition Outcomes / SCL Universal Offers
There was, of course, a longer, more detailed list, but these three were repeated time and time again.
What happens next?
These workshops were really helpful for me in showing how much consensus existed about what should go in a core dataset, but also the problems and challenges being faced in trying to collect and use data. This is, of course, only the first step. I want to get as many views as possible on the things we discussed in the workshops. I’ll be posting a blog next week on how you can get involved, but if you have any questions in the meantime, please get in touch at library-data@culture.gov.uk or leave a comment below.
If you’re interested in what goes on at a hackday, Open Data Devon, with Devon Libraries, are running a Libraries Open Data Discovery Day on 19 March.
To keep up to date with Taskforce activities, remember to follow us on twitter, or subscribe to our blogs.