[Editor’s note: Guest post written by Catherine Cooke, Application Support Officer for the TriBorough shared library service (Hammersmith & Fulham, Kensington & Chelsea, Westminster) and the current Chair of the BIC Libraries Committee. Catherine describes how TriBorough have improved the visibility of their catalogue to internet search engines through the use of linked data, positioning the library where its users - and potential users - are.]
Where have we come from?
For many years now, libraries have published their catalogues online. These catalogues are now very mature, offering both simple and more advanced searching for print and electronic resources, showcasing new stock, highlighting events, special collections, twitter feeds and the like. Running from the authorities’ underlying library management systems, they are largely based on MARC.
MARC was developed back in the very early 1970s specifically for computer-based bibliographic systems, the MAchine Readable Catalogue. It has constantly developed to keep pace with knowledge systems and has worked extremely well for the purposes for which it was designed. It is easy to export and import records, share catalogue resources – 245 is always the title field, 100 personal author and so forth – and easy to map the fields into online displays, for both staff and customers’ use.
With the advent of the internet, however, the rigid structure of MARC is not so appropriate. Internet search engines, such as Google, rely far more on links between data and cannot fully exploit a MARC record. The more links to an element, the more relevant it will be deemed.
Forward thinking
Work has been done for a number of years to define a new bibliographic record format that search engines can exploit. In 1998, IFLA recommended restructuring catalogue databases to reflect the conceptual structure of resources, an initiative known as Functional Requirements for Bibliographic Records, or FRBR for short. Rather than use a flat record concept, FRBR uses entities and relationships. The full report is available and the basic model is shown in the infographic below.
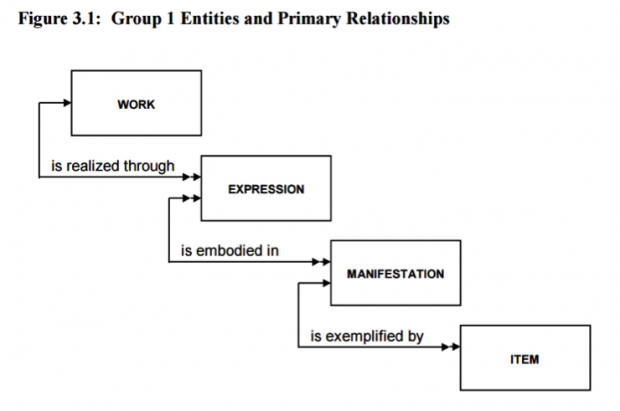
There are now a few standards based on this model. One is Resource Description & Access – RDA. Find out more at RDA FAQs. Another is BIBFRAME, developed by Zepheira for The Library of Congress, which puts the Work, Instance and Item at the heart and links it to those people, events and other data associated with it, as shown in the graphic below.
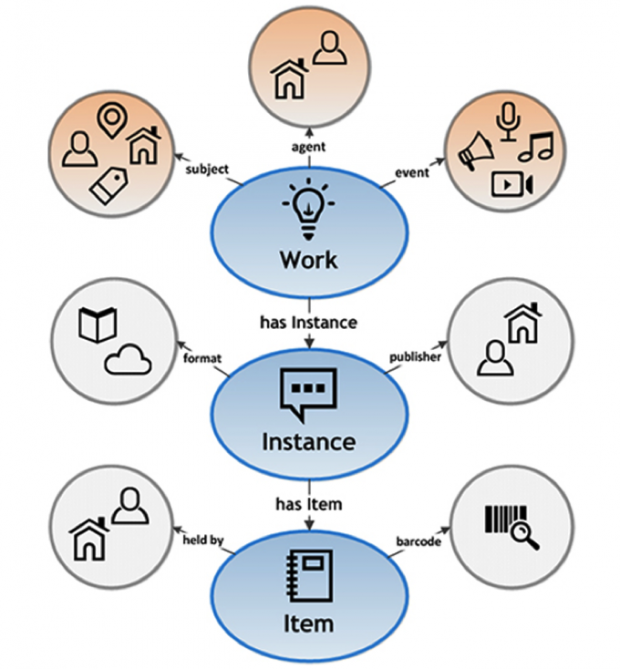
A new way of presenting the catalogue
Our library system supplier, SirsiDynix, offers a service, BlueCloud Visibility, which involves the entire catalogue being downloaded to Zepheira. They convert it to Bibframe and make it available on the internet as part of a Library Link initiative along with the data from many other library services. We did this last year, sending updates twice a month. There was a small amount of set-up to do at our end; most of the required information about our libraries we had already set up for other “BlueCloud” facilities. We also had to get our respective IT departments to set up a URL for each authority to link to our catalogues. Though we share the library system and resources are available to all, we run 3 instances of the public facing catalogue to allow for corporate branding, specialisms and so forth.
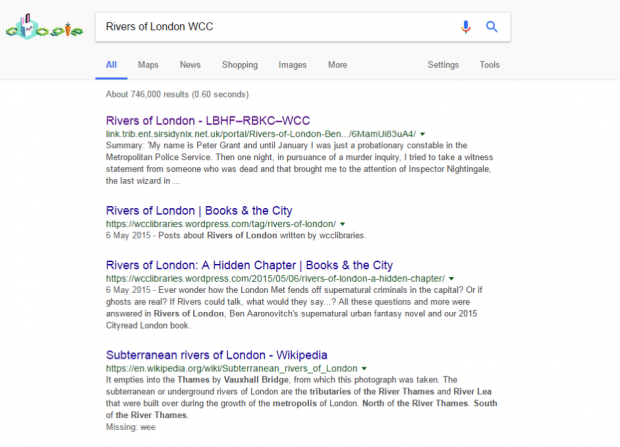
Now, when someone geographically within our authorities types a title into Google, our Library Link hit should be high on the list of hits. If you are not within our authorities, or do not allow your device to track your location, you can see this by putting WCC, RBKC or LBHF after the title. For example, search for Rivers of London WCC. The hit is first on the list as shown in the screenshot below.
Follow that link, and you see the Library Link page.
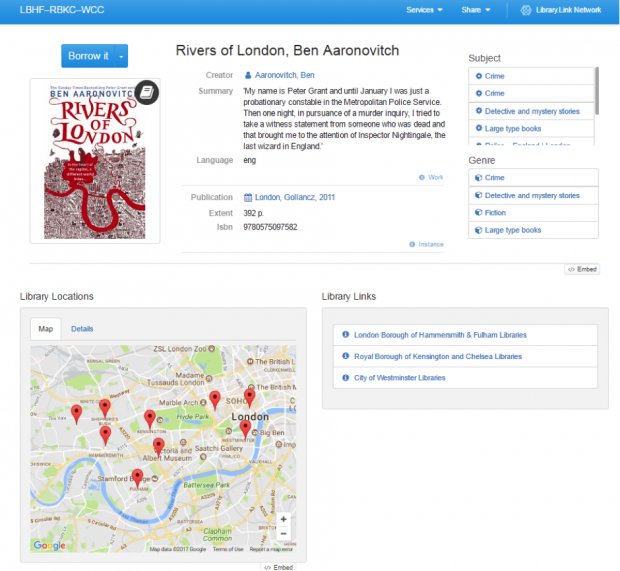
From here, you can click Borrow it or use the drop down to select a specific library and be taken to our catalogue. Or follow links for the author or subject and genre terms, all of which take you to other resources in our catalogue, from which you can follow the link to our catalogue.
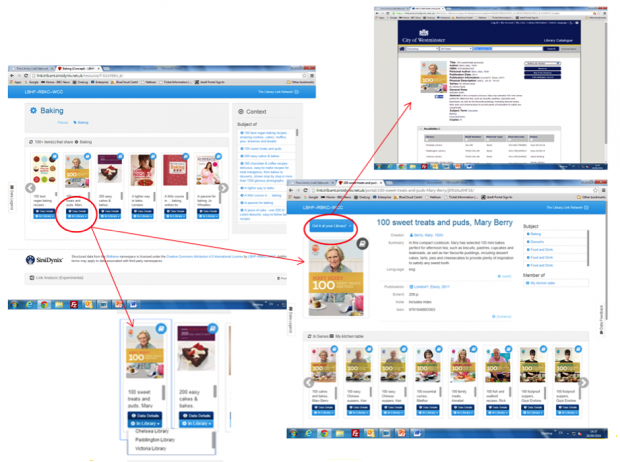
You can access our library details and opening hours from the LBHF-RBKC-WCC on the blue banner across the top. If the author is both a creator and a contributor to other titles, those relationships will be made clear:
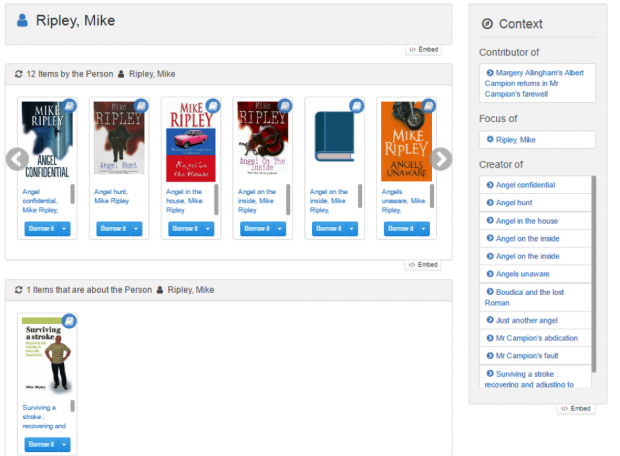
Progress so far
We’ve been fully live for about 4 months now, so I thought it worth having a look at Google Analytics and seeing how the top ten sites referring customers to our catalogue instances had changed from the same 4 months last year.
| Category | Sessions 2016 | Sessions 2017 |
|---|---|---|
| Outlook Live | 1,106 | 1,053 |
| Worldcat | 1,042 | 720 |
| Libraries blog | 164 | 37 |
| Old catalogue | 163 | 74 |
| Portal | 98 | |
| Website | 88 | |
| Camden | 63 | |
| Other | 59 | |
| Search engine | 45 | 70 |
| Yahoo | 26 | 288 |
| BC Visibility | 21 | 2,598 |
| Unknown | 19 | 52 |
| AOL | 7 | |
| MSN | 112 | |
| Google docs | 13 | |
| Council webpage | 44,045 | 45,000 |
| Public PC home page | 2,215 | 2,025 |
| Main stock supplier (staff use) | 107 |
The latter 3 entries were excluded from the chart below
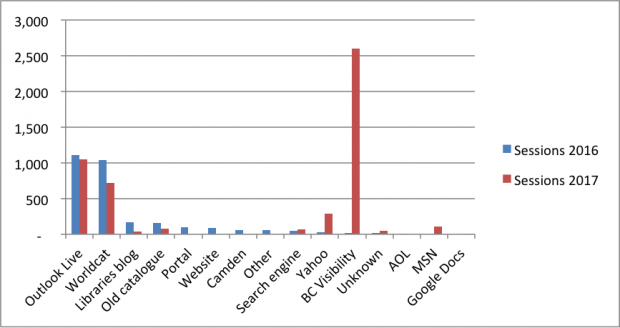
BlueCloud Visibility is now what refers most people to our catalogue. Sadly, it has not been possible to detect a corresponding rise in membership or issues, but it is perhaps early days still.
The big advantage of this sort of approach to discovery, whichever linked data model is actually used, is that the customer does not have to know the URL of the library catalogue or of a portal, or first search for the catalogue in order to search that to find a title. They just do what most people now do when they want to know something – they put it into Google.
We live in a connected world now – libraries need to be in that world. As more people search and create links to this data, and as more libraries add their catalogues to linked data databases, so the search engines will get familiar with it and bring more matches to the fore. The library is positioning itself where its customers and potential customers are.
-------------------
Please note, this is a guest blog. Views expressed here do not necessarily represent the views of DCMS or the Libraries Taskforce