The thorny issue of library data - what should be collected, how can we improve the collection and analysis of it and how can we ensure consistency and make better use of it - has been central to Libraries Deliver: Ambition. Its action plan included the commitment to define and publish a core data set, creating a transparent and automated (where possible) process to gather and share it and the Taskforce's blog has seen many contributions exploring the issues and challenges surrounding it.
Taskforce aspirations have always been to work towards a consistent and widely collected and published dataset. One which can inform and improve local library service delivery, as well as being used for advocacy purposes at local and national level. See previous blogs on the publication of the basic dataset and the core dataset for the history of this work.
The publication of the basic dataset was a first step but only takes us so far along the road, so this summer the Taskforce rebooted its open data aspirations with a commitment of £15,000. On 5 August the Department for Digital, Culture, Media and Sport (DCMS) hosted (in a rather dreary windowless room!) a workshop for Taskforce members, front-line library practitioners and data experts to reflect on what had already been achieved and what the next steps should be.
Remind me where we were….?
The workshop started with hearing from colleagues in DCMS about the history of open data and the government’s commitment to it. As well as being responsible for libraries, DCMS also leads for open data for government and this helped to reinforce the continued importance of improving the quality of and access to data. Good quality data enables better services, better policy and better government operations (the 'virtuous circle' described below).
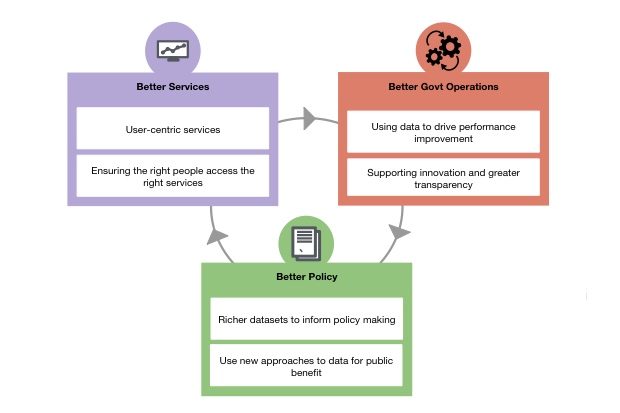
There are many examples of how good quality open data can amplify good work and help shape better services, often using the power of the crowd. The workshop heard from some of the library services and local authorities who are at the forefront of open data and a common theme was the view that the library service (and other council services) should be publishing as much as they can. As Aude Charillon from Newcastle said, “The data belongs to local citizens and the authority has a duty to give it back to them.”
As a newcomer to this project, this comment really hit home. This is not just about collecting and analysing data ‘in house’ to the benefit of the service or to local and central government, but to make it visible to the people it comes from. For me this really connects back to the intent of the Local Government Transparency Code and the principles of Open Government to increase democratic accountability and make it easier for local people to contribute to the local decision making process and help shape public services.
Core dataset schema
Having got ourselves in the mood, the workshop cracked on with an intensive discussion about the core dataset schema. The core dataset is intended to be a series of data which all library services will collect, use and publish to help inform and improve local library service delivery, as well as being used for advocacy purposes at local and national level (when aggregated). According to the dictionary a schema is a representation of a plan or theory in the form of an outline or model so in this context the schema provides the structure and definitions for the database.
Although participants agreed with many elements, lots of questions and issues were raised such as:
- the complexity of capturing opening hours in a consistent way
- how to capture whether a library is co-located and with what it's co-located
- how events data might be categorised
- how the lack of consistency in collecting visits data could undermine comparisons
Discussions about user data also generated lively debate. There is potential value in being able to map users, and tie that to other demographic data, but there were varying views about how comfortable services would be in using postcode data. It’s vital to use data appropriately which is why DCMS published the Data Ethics Framework, this document will help guide further thinking on the subject.
Financial information is another area where there isn't a straightforward answer. That is not to say we shouldn’t tackle it, but we also shouldn’t let it hinder us pushing on with what we can do. To that end there was a strong view around the table that we certainly could get on with developing a ‘straw man’ technical schema quickly which could be trialled by a number of councils.
Operation Persuasion
Participants then broke into groups to explore the different audience(s) that need to be on-side to make this work successful. Important influencers were thought to be Heads of Service and front-line staff and practitioners highlighting that you can’t drive change purely from the top, you need the front-line as well. The case needs to be made strongly to those groups to engage, educate and enthuse. We came away with a number of suggested messaging approaches, along with ideas for outputs. Other significant groups might include senior officers / corporate management board and vendors / suppliers.

Interestingly (for me!) there was a strong view that although this may seem on the face of it to be a technical challenge, the greater issue is cultural and that should be the primary focus. Front-line staff need to be up-skilled in a positive and supportive way, building competence and capability alongside an evolution of business as usual to ensure that collecting and using data is firmly part of job specifications and core competencies.
We wound up the afternoon in our windowless room by thinking about future aspirations and the top of these was measuring impact. Wide use of an agreed schema will, we hope, provide better and more consistent quantitative data - for example how many events have libraries put on? - but cannot answer the qualitative - what impact on attendees did they have?
Another significant aspect was the importance of this work being sector-led and shaped. DCMS clearly has an interest from the national perspective but the success (or failure) of achieving the Ambition captured back in 2016 - itself shaped through extensive engagement and consultation with the sector - rests with library services themselves. So…

Where do we go from here?
We have identified 3 initial phases of work.
Phase 1
Creating test datasets for the core dataset schema in September. This covers drafting the schema for datasets on individual libraries, active library membership, events, physical visits and stock. We are really pleased that Dave Rowe (Libraries Hacked), Aude Charillon (Newcastle) and Claire Back (Plymouth) have volunteered to take this task on and by the end of phase 1 we will have a draft schema and definitions using sample outputs from Newcastle and Plymouth. They’ll also be working on sample visualisations and insights from the data.
Phase 2
Test the schema with a wider group of library services over October and November. This is where we really need you! We’d love to hear from you if you want to get involved with this project so please get in touch with us at library-data@culture.gov.uk.
This phase will aim to:
- create more visualisations using the higher number of library service data to address the “show, not tell” principle which workshop participants felt was important
- build any tools required to make the input of data against the schema easier / reduce error
- establish what financial data should best be included
Phase 3
Create guidance and run workshops in the new year on using the schema.
If you’d like to get involved in phase 2 or with any of this work at all please get in touch with us at library-data@culture.gov.uk.
Keep up to date with this work by subscribing to the blog.