In August 2019 a group of people including members of the Libraries Taskforce, library staff and data enthusiasts gathered together for a workshop hosted by DCMS to revive work on creating a core dataset for public libraries. Read about that workshop and the background to it on the DCMS Libraries Blog.
Developing a data schema
A small group of us were really enthused by the workshop and keen to start making some practical progress on creating a schema for a core dataset for public libraries. A schema describes a set of standards for publishing data, providing definitions and structure for the datasets. Publishing to a set of standards will help services compare and analyse data, and enable open applications to be built. We wanted to move on from theoretical discussion towards an actual schema to test with library services, really delving into issues and working them through with the frontline staff who would need to be on board.
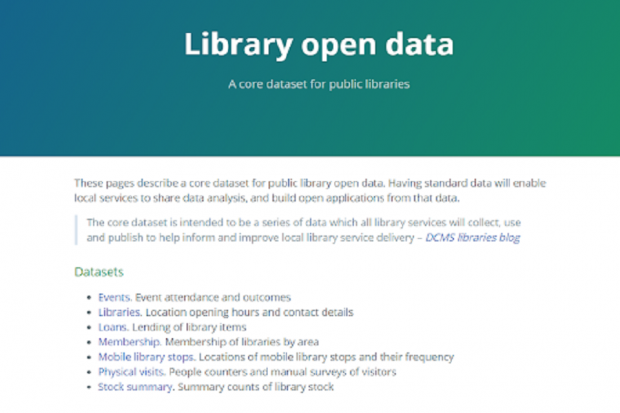
At this stage we have concentrated on six datasets. Dave Rowe (Libraries Hacked) had already been working on a schema for mobile library stops, so this was included to complement the physical libraries dataset. The full list of datasets is:
- Events. Events attendance and outcomes
- Libraries. Location opening hours and contact details
- Loans. Lending of library items
- Membership. Membership of libraries by area
- Mobile library stops. Locations of mobile library stops and their frequency
- Physical visits. People counters and manual surveys of visitors
- Stock summary. Summary counts of library stock
Testing the schema
Regardless of how good a schema is, it can only work if it is responsive to and meets the needs of those who will be using it - library services themselves. We used the DCMS Libraries blog and the Libraries Connected Innovators Network to put out a call for willing testers and we were thrilled that 9 more came forward, along with Newcastle and Plymouth. They were a good mix, with differing levels of experience. This was important as we wanted the schema to be easy to use and understandable to those who may not be as used to working with data. Discussions started through dedicated Slack channels, with a second workshop at DCMS (with the added highlight of a fire drill) to get more hands on, meet colleagues face to face, answer questions and talk through the datasets.
We’ve created a website to host the data schema at https://schema.librarydata.uk. Each dataset has a page which includes:
- a definition of the dataset
- how the data can be collected, some with links to templates
- a sample data row and link to an example dataset
- field notes which include a record of some of the discussions that took place
- potential problems
- suggestions for how the data might be updated by services
- how the data might be used - examples of what might be done with the data, locally and nationally
- suggested future enhancements
More testing was done over the New Year and into January and discussions with the test services helped us to identify where there may be problems and also to see how easy it would be to adapt existing data they may already be collecting to fit the schema. Much of this data is already collected and used internally, and feedback suggests that for some of the datasets this would be a relatively straightforward task. All of the test services managed to produce at least one of the datasets to the schema during this phase.
Refining the schema
There are some further discussions and work to be done on some of the datasets. The events dataset for example uses the seven outcomes from the Ambition document, but some authorities record their outcomes against Libraries Connected Universal Offers. The schema allows for reporting on both, but it would be good to explore this further - any thoughts would be very welcome! Detailed data on events will help to capture and report on the impact of libraries, something which is long overdue and has perhaps become even more relevant with experiences during the Covid-19 pandemic
The visits dataset highlighted the many different ways that libraries count their visits, from automatic people counters to manual visits taken at set times each year. The schema allows for this, but we think it’s worth having further discussions to understand how the consistency and quality of this data could be improved.
There is also some more work to be done on automation. Some of the datasets such as loans and stock summaries are extracted from the LMS and this could be an automatic process. We’re interested to know if any services are already doing this and how methods can be shared between those services that use the same LMS.
Promoting the schema
In some ways, creating the schema was the easy part; as was highlighted in the previous blog, the biggest challenge is cultural. How can we engage services and library staff to understand how important this data could be? How do we make sure that staff have the skills and confidence to take on a data role? We hope that some of the examples on the schema site will go some way to highlighting what can be done if data is published in an open and standard format.
In March we started the next phase of this work, talking about the schema to heads of service at the Libraries Connected Advisory Committee meeting and also to the LC Information and Digital Offer group. At both the schema was well received, but then Covid-19 happened and the focus for services was elsewhere. But as libraries start to look at reopening and to consider the challenges in a post-Covid world, consistent, reliable data becomes more important than ever.
We’re always happy to hear from people who want to find out more or want to get involved. Join in the discussion on Slack, leave your comments below this blog or email jenny.harland@dcms.gov.uk and she’ll put you in touch with us.
DCMS says:
We’re really pleased with the work that Claire, Aude and Dave have done with the schemas. But the big question is what happens next and how do we integrate use of the schemas into everyday business as usual for library services? Covid-19 may have slowed us down a bit, but we are determined to press forward. Pre-lockdown engagement with HoS via Libraries Connected started well and over the rest of the year we aim to build on that, including creating targeted guidance and developing workshops to promote the use of schemas. So look out for these and sign-up in due course.
2 comments
Comment by Tim Coates posted on
Why don't you just use the ILMS (the integrated library management system) that operates in each library?
They already hold
- Branch details
- Contact details
- Actual opening hours
- Loan information
- Membership information
- Details of stock holdings and acquisitions. etc
It would be perfectly easy for branches to complete and end-of-day report which lists events, visitor counts, user feedback
The ILMS also have a mechanism for collecting and pooling data - via Libscan.
A council could post monthly expense reports
The CIPFA dataset also has valuable historic information. It should be included
All this could be hosted continuously by the ILMS on a national open website, with access by passcode for any sensitive data.
I'm just suggesting you don't reinvent the wheel but use the one for which we already pay about £25m per annum
Glad to help if I can
Comment by Tim Coates posted on
If you were to ask The Libraries Consortium (formerly The London Libraries Consortium) and Sirsidynix, their system provider, you will find that they can gather nearly all the data you need every day. Either they hold it now, or they could collect it in simple daily reports from each branch library.
You also need to collect historical data, for example, what loans and visits were this time last year. That will help libraries to manage their growth
(I notice you didn't post my last comment. Can I assume it arrived? and please can you acknowledge this one? Thanks)